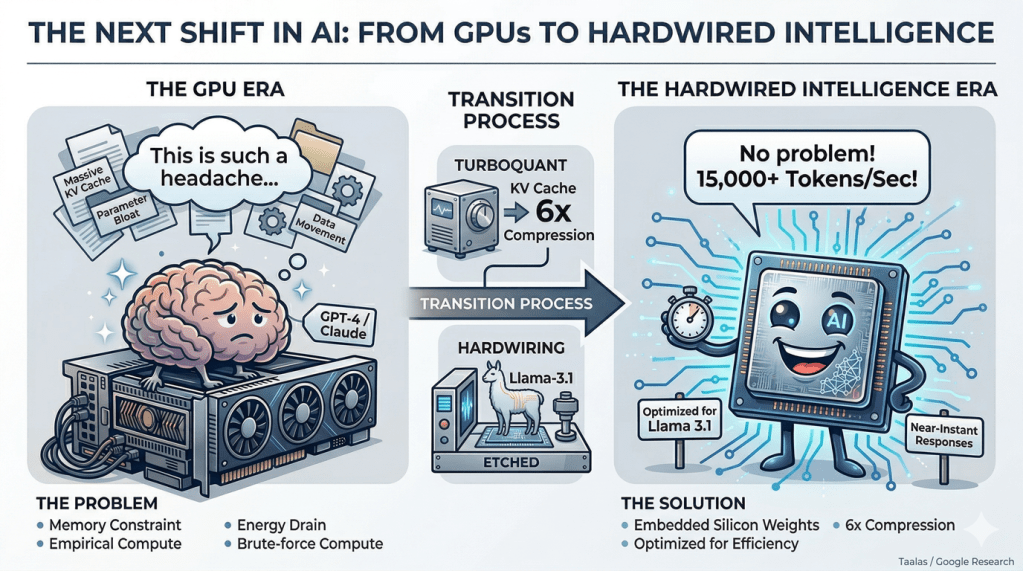
The Next Shift in AI: From GPUs to Hardwired Intelligence
For years, the story of artificial intelligence has been simple: bigger models + more GPUs = better intelligence.
That formula gave us ChatGPT, Claude, and Gemini. It also created an industry powered by massive data centers, expensive hardware, and ever-growing energy demands. But beneath the surface, something is breaking. AI is running into fundamental limits—not of intelligence, but of efficiency.
A new wave of ideas—combining hardwired AI chips and extreme compression techniques like TurboQuant—is pointing toward a very different future.
The Problem: AI Is Hitting a Wall
Modern AI systems are incredibly powerful—but deeply inefficient. Most people assume AI is limited by compute. In reality, the bigger constraint is memory. Language models don’t just store parameters. They also maintain a KV cache—a growing working memory that expands with every token in a conversation.
At scale, this becomes a serious issue:
The memory required to run AI can exceed the memory required to store it.
This leads to:
- Constant data movement between memory and compute
- Increased latency
- High energy consumption
- Exploding infrastructure costs
GPUs manage this through brute force. But they were never designed specifically for AI—they are general-purpose systems solving a specialized problem. And that mismatch is starting to show.
The First Shift: Turning Models Into Hardware
What if we flipped the paradigm?
What if the model itself became the hardware?
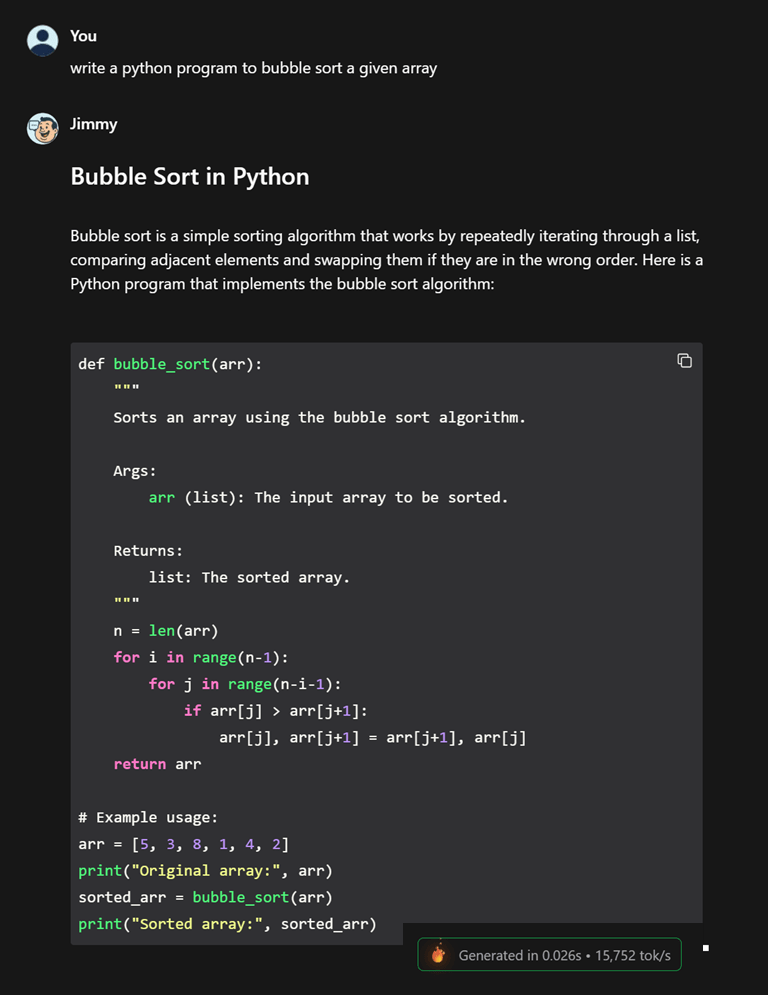
This is the idea behind emerging chips like the Taalas HC1. Here, the model’s weights are embedded directly into silicon. Compute and memory are tightly integrated. The system is no longer general-purpose—it is purpose-built for one neural network. Try their chatbot generating output at 15000 tokens/s : https://chatjimmy.ai/ compared to Claude Sonnet running at 60 tokens/s .
I asked JimmyChat to write a python function to sort an array , got the out at Generated in 0.026s • 15,752 tok/s .
At 15000 tokens / s , imagine an agent generating code . The PR reviews will become painful if there are no proper guardrails in place. Humans will run out of things to tell it !! ( just a crazy thought 😉 )
| The result is dramatic: | But there’s a trade-off. These systems sacrifice flexibility: |
| + Orders-of-magnitude faster inference + Near-instant responses + Significant energy efficiency | – Models can’t be easily updated – Architectures are fixed – Adaptability is limited |
This works because it eliminates one of the biggest inefficiencies in modern AI: data movement. They solve compute inefficiency—but not everything. The current chip is using is Llama 3.1 8B , which is not great .
The Second Shift: Compressing Intelligence
If the first shift removes compute inefficiency, the second tackles something even more fundamental:
The cost of memory.
Google’s TurboQuant introduces a breakthrough in how AI systems handle their working memory. It compresses the KV cache—the growing memory used during conversations—by up to 6×, while also accelerating attention computation.
The problem (today)
When an AI model talks to you, it doesn’t just “think once.”
It remembers every token in the conversation using something called a KV cache.
- Longer conversation → more memory needed
- More users → memory explodes
- This memory often becomes bigger than the model itself
👉 Think of it like: The model is the brain, but the KV cache is its working memory
What TurboQuant does
TurboQuant compresses this working memory (KV cache) by ~6× without losing accuracy. So instead of storing: 16 bits per value → it uses ~3 bits
Scenario: Running a 13B model chatbot
| Without TurboQuant | With TurboQuant |
|---|---|
| – Model weights (4-bit): ~7–8 GB – KV cache (long chat / multiple users): 10–20 GB+ | – KV cache reduced by ~6× – KV cache: 10–20 GB → ~2–3 GB |
| Total Memory needed: ~24–32 GB VRAM | Total memory needed : → ~10–12 GB |
| What hardware do you need? – RTX 4090 (24GB) → barely enough – Or 2× GPUs → expensive setup | Now what hardware works? RTX 3060 (12GB) ✅ Even high-end laptops with GPU ✅ |
| 💸 Cost: GPU: ₹1.5L – ₹2L ($1800–$2500) | 💸 Cost: GPU: ₹25K – ₹35K ($300–$400) |
Individually, this is powerful. But combined with specialized hardware, it becomes transformative.
The Future: AI as Specialized Infrastructure
The real breakthrough isn’t just hardware or compression—it’s the combination of both.
- Hardwired chips remove compute inefficiency
- Compression techniques remove memory inefficiency
Together, they eliminate the two biggest bottlenecks in AI. This leads to a new kind of AI stack:
- Training remains flexible and compute-heavy
- Frontier models run on high-performance systems
- Deployment shifts toward specialized, efficient hardware
Over time, this enables:
- Faster, cheaper AI at scale
- Real-time intelligent systems
- More accessible and energy-efficient deployments
The future of AI is not about one piece of technology replacing another.
It’s about a transition from:
General-purpose computing
To:
Specialized intelligence systems designed for efficiency
Final Thought
The next phase of AI won’t be defined by who builds the biggest model. It will be defined by who builds the most efficient system. Because the future of AI is not just smarter—it’s leaner, faster, and deeply integrated with the hardware it runs on.